Анализ данных из постов Instagram*
* Instagram принадлежит компании Meta, признанной экстремистской и запрещенной на территории РФ.
В этом примере мы продемонстрируем, как можно проанализировать данные из датасета "instagram ads" на Kaggle. Данные в этом датасете представляют собой посты из социальной сети Instagram со всевозможными атрибутами (комментарии, лайки, информация об аудио и видео и прочее).
Загрузка исходных данных
Для начала загрузим данные. Это можно сделать либо в ручную через Мастер загрузки, либо с помощью, например, такого кода на Python.
Здесь мы задаем URL страницы датасета на Kaggle, проверяем, что скачанный файл является файлом .zip, и если это так, то распаковываем его содержимое во временную директорию, а затем загружаем в Tengri все распакованные файлы с помощью функции tngri.upload_file.
import urllib.request
import os
import zipfile
import tngri
zip_url = 'https://www.kaggle.com/api/v1/datasets/download/geraygench/instagram-ads'
urllib.request.urlretrieve(zip_url, 'data.zip')
temp_dir = 'temp'
uploaded_files = []
try:
with zipfile.ZipFile('data.zip', 'r') as zObject:
zObject.extractall(path=temp_dir)
for file in os.listdir(temp_dir):
cur_file = tngri.upload_file(os.path.join(temp_dir, file))
uploaded_files.append(cur_file)
except:
print('Not a valid zip file')
print('Uploaded files:')
i = 1
for file in uploaded_files:
print(i, file)
i += 1Uploaded files:
1 niemkupghwwz.jsonТеперь зададим имя таблицы и запишем в нее данные из загруженного файла с помощью функции read_json. На случай, если файлов загрузилось несколько, сделаем это в цикле.
table_name = 'instagram_source'
created = False
for file in uploaded_files:
if not created:
tngri.sql(f"create or replace table {table_name} as select * from read_json('{file}')")
created = True
else:
tngri.sql(f"insert into table {table_name} select * from read_json('{file}')")
print(f'Created table: {table_name}')
count = tngri.sql(f'select count(*) from {table_name}')
print(f'Created table row count: {count[0,0]}')Created table: instagram_source
Created table row count: 2800Выведем первые 5 строк загруженных данных, чтобы зрительно проверить, что загрузка прошла успешно.
SELECT * FROM instagram_source
LIMIT 5;Done in 1.1 sec
+-----------------------------------------------+---------------------+---------+-------------+-----+
| inputUrl | id | type | shortCode | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3351813129396710000 | Video | C6ECEhTLlj7 | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3335943316421300000 | Video | C5LpsWOIUc8 | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3319217982042080000 | Sidecar | C4QOysvtPUU | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3372181927023210000 | Sidecar | C7MZZiWNffn | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3369947094264730000 | Video | C7EdQcJgkwr | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+Теперь создадим таблицу raw_instagram_post и загрузим в нее эти данные.
Для тех столбцов, в которых мы обнаружили вложенную структуру JSON, укажем тип JSON. Для некоторых столбцов укажем удобные нам новые имена и нужные типы данных (например, TIMESTAMP). Зададим ограничение, что значение идентификатора ig_post_id не должно быть пустым, чтобы отбросить потенциальные невалидные фрагменты данных.
CREATE OR REPLACE TABLE raw_instagram_post AS
SELECT
inputUrl,
id AS ig_post_id,
TYPE,
shortCode,
caption,
hashtags,
mentions,
url,
dimensionsHeight,
dimensionsWidth,
commentsCount,
firstComment,
displayUrl,
images,
videoUrl,
alt,
likesCount,
videoViewCount,
videoPlayCount,
timestamp::TIMESTAMP AS post_ts,
ownerFullName,
ownerUsername,
ownerId,
productType,
videoDuration,
isSponsored,
isPinned,
locationName,
locationId,
error,
description,
paidPartnership,
sponsors::JSON AS sponsors,
taggedUsers::JSON AS taggedUsers,
musicInfo::JSON AS musicInfo,
coauthorProducers::JSON AS coauthorProducers,
latestComments::JSON AS latestComments,
childPosts::JSON AS childPosts
FROM instagram_source
WHERE ig_post_id IS NOT NULL;Done in 1.7 sec
+--------+
| status |
+--------+
| CREATE |
+--------+Выведем первые 5 строк таблицы, чтобы зрительно проверить, что данные в ней соответствуют нашим ожиданиям.
SELECT * FROM raw_instagram_post
LIMIT 5;Done in 1.2 sec
+-----------------------------------------------+---------------------+---------+-------------+-----+
| inputurl | ig_post_id | type | shortcode | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3351813129396710000 | Video | C6ECEhTLlj7 | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3335943316421300000 | Video | C5LpsWOIUc8 | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3319217982042080000 | Sidecar | C4QOysvtPUU | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3372181927023210000 | Sidecar | C7MZZiWNffn | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+
| https://www.instagram.com/fjallravenofficial/ | 3369947094264730000 | Video | C7EdQcJgkwr | ... |
+-----------------------------------------------+---------------------+---------+-------------+-----+Подготовка данных
Теперь проанализируем вложенную структуру JSON в столбце musicinfo, использовав для этого функции unnest и json_keys:
SELECT
unnest(keys) AS musicinfo_keys,
keys_count
FROM
(SELECT
json_keys(musicinfo) AS keys,
count(*) AS keys_count
FROM raw_instagram_post
WHERE musicinfo IS NOT NULL
GROUP BY 1) t;Done in 1.1 sec
+--------------------------+------------+
| musicinfo_keys | keys_count |
+--------------------------+------------+
| artist_name | 1176 |
+--------------------------+------------+
| song_name | 1176 |
+--------------------------+------------+
| uses_original_audio | 1176 |
+--------------------------+------------+
| should_mute_audio | 1176 |
+--------------------------+------------+
| should_mute_audio_reason | 1176 |
+--------------------------+------------+
| audio_id | 1176 |
+--------------------------+------------+Извлечем данные из структуры JSON с помощью функции json_extract и запишем их в новую таблицу silver_instagram_musicinfo, столбцы которой — это ключи из исходной структуры JSON (внутри musicinfo), которые мы увидели на предыдущем шаге, а в столбец ig_post_id запишем id из исходной таблицы instagram_post.
Обратите внимание, что функцию json_extract мы используем здесь не более одного раза для одного столбца исходной таблицы. Это позволяет сэкономить время и вычислительные мощности, так как после однократного извлечения этих данных обращение к ним будет происходить практически моментально.
|
CREATE OR REPLACE TABLE silver_instagram_musicinfo AS
SELECT DISTINCT ig_post_id,
arr[1] AS 'artist_name',
arr[2] AS 'song_name',
arr[3]::bool AS 'uses_original_audio',
arr[4]::bool AS 'should_mute_audio',
arr[5] AS 'should_mute_audio_reason',
arr[6]::bigint AS 'audio_id'
FROM (SELECT ig_post_id, musicinfo,
json_extract(musicinfo, ['artist_name',
'song_name',
'uses_original_audio',
'should_mute_audio',
'should_mute_audio_reason',
'audio_id'])
arr
FROM raw_instagram_post
WHERE musicinfo IS NOT NULL
) e;Done in 1.1 sec
+--------+
| status |
+--------+
| CREATE |
+--------+Выведем первые пять строк из получившейся таблицы, чтобы зрительно проверить данные в ней.
SELECT * FROM silver_instagram_musicinfo
LIMIT 5;Done in 1 sec
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| ig_post_id | artist_name | song_name | uses_original_audio | should_mute_audio | should_mute_audio_reason | audio_id |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| 3361389062866375005 | "fjallravenofficial" | "Original audio" | true | false | "" | 1091589181917200 |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| 3362166784222944940 | "Lyle Workman" | "Sun Beyond the Darkness" | false | false | "" | 700744903595866 |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| 3370702174072339576 | "victoriassecret" | "Original audio" | true | false | "" | 969258887793092 |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| 3365659145996406849 | "victoriassecret" | "Original audio" | true | false | "" | 1856092344873079 |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+
| 3367926439711140761 | "asos" | "Original audio" | true | false | "" | 1428332318047391 |
+---------------------+----------------------+---------------------------+---------------------+-------------------+--------------------------+------------------+Теперь посмотрим на столбец исходной таблицы с информацией о затэганных пользователях taggedUsers. Обратим внимание, что в нем данные представлены в виде массивов. Используя функции unnest и json_extract, создадим таблицу silver_instagram_taggeduser:
CREATE OR REPLACE TABLE silver_instagram_taggeduser AS
SELECT DISTINCT
ig_post_id,
arr[1]::varchar AS 'full_name',
arr[2]::bigint AS 'user_id',
arr[3]::bool AS 'is_verified',
arr[4] AS 'profile_pic_url',
arr[5] AS 'username'
FROM
(SELECT
ig_post_id,
json_extract(users, ['full_name',
'id','is_verified',
'profile_pic_url',
'username']) AS arr
FROM
(SELECT
ig_post_id,
unnest(json_extract(taggedUsers, '[*]')) AS users
FROM raw_instagram_post
WHERE taggedUsers IS NOT NULL)
un) t;Done in 1 sec
+--------+
| status |
+--------+
| CREATE |
+--------+Выведем первые 5 строк созданной таблицы silver_instagram_taggeduser и визуально проверим данные в ней.
SELECT * FROM silver_instagram_taggeduser
LIMIT 5;Done in 1 sec
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| ig_post_id | full_name | user_id | is_verified | profile_pic_url | username |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 3368467612563246843 | "Candice" | 43114731 | true | "https://scontent.cdninstagram.com/v/t51.2885-19/436426783_716232097252223_2080875243016028171_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent.cdninstagram.com&_nc_cat=1&_nc_ohc=VZz3Y6G6kCgQ7kNvgEfJgX3&edm=APs17CUBAAAA&ccb=7-5&oh=00_AYDeE3YwxCQxVEK-3DLy0AK8cSmaFu3SVuwsUluh0pQ2Hg&oe=66526CB7&_nc_sid=10d13b" | "candiceswanepoel" |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 3371457031159064630 | "Brittany Xavier" | 739181077 | true | "https://scontent.cdninstagram.com/v/t51.2885-19/299498992_480162533527636_8112607220645623732_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent.cdninstagram.com&_nc_cat=104&_nc_ohc=D83lh8W9o-EQ7kNvgEAZo1_&edm=APs17CUBAAAA&ccb=7-5&oh=00_AYCI_FerVMUvMEltLhAaANlfFdtezWw90dIOCff-oNuiLQ&oe=66526DD9&_nc_sid=10d13b" | "brittanyxavier" |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 3350535229969664632 | "dev scudds" | 200671402 | false | "https://scontent.cdninstagram.com/v/t51.2885-19/316332449_539815587596795_7700370950656909913_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent.cdninstagram.com&_nc_cat=111&_nc_ohc=yt51b9U7YQcQ7kNvgGr0PqA&edm=APs17CUBAAAA&ccb=7-5&oh=00_AYC_DbQKZ56A_C_kK4oCamtB10dpgXWxNr9dupqkTHIKZA&oe=665259D4&_nc_sid=10d13b" | "devscudds" |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 3355576548572106408 | "Roxie Nafousi" | 182064334 | true | "https://scontent.cdninstagram.com/v/t51.2885-19/432688376_299228906523099_7608649815950644359_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent.cdninstagram.com&_nc_cat=1&_nc_ohc=mNDTJLE0sakQ7kNvgFoinRd&edm=APs17CUBAAAA&ccb=7-5&oh=00_AYDyLDXyYkSqF7jeJ7SDKO-ATM7WbbH8OYqhw_GOjiGygQ&oe=66526921&_nc_sid=10d13b" | "roxienafousi" |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+
| 3369046462609537802 | "ASOS MAN" | 640874843 | true | "https://scontent.cdninstagram.com/v/t51.2885-19/244277018_902025494057602_3929487210907869376_n.jpg?stp=dst-jpg_s150x150&_nc_ht=scontent.cdninstagram.com&_nc_cat=110&_nc_ohc=5aRpL0ZaRW8Q7kNvgFG0_9g&edm=APs17CUBAAAA&ccb=7-5&oh=00_AYBmZ6qVQtwRziMSsl8tGtlX7u4-RnYXa-MxQIaIEKyc7Q&oe=66527A51&_nc_sid=10d13b" | "asos_man" |
+---------------------+-------------------+-----------+-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------+Теперь посмотрим на столбец исходной таблицы с информацией о комментариях latestComments. В нем данные представлены в виде массива комментариев. Чтобы узнать, какие ключи встречаются внутри этих массивов, используем функции unnest, json_keys и json_extract и выполним такой запрос:
SELECT
unnest(keys) AS comment_keys
FROM
(SELECT
json_keys(comments) AS keys,
FROM
(SELECT
ig_post_id,
unnest(json_extract(latestComments, '[*]')) AS comments
FROM raw_instagram_post
WHERE latestComments IS NOT NULL) un
GROUP BY 1) t;Done in 1 sec
+--------------------+
| comment_keys |
+--------------------+
| id |
+--------------------+
| text |
+--------------------+
| ownerUsername |
+--------------------+
| ownerProfilePicUrl |
+--------------------+
| timestamp |
+--------------------+
| likesCount |
+--------------------+
| repliesCount |
+--------------------+
| replies |
+--------------------+Извлечем комментарии в таблицу silver_instagram_comments аналогичным образом, как мы это сделали выше для пользователей и исполнителей.
Обратим внимание, что в этой таблице likesCount и repliesCount — это количество лайков и ответов на данный комментарий (а не на исходный пост).
CREATE OR REPLACE TABLE silver_instagram_comments as
SELECT DISTINCT
ig_post_id,
arr[1]::bigint AS comment_id,
arr[2] AS 'text',
arr[3] AS 'ownerUsername',
arr[4] AS 'ownerProfilePicUrl',
arr[5]::timestamp AS 'comment_ts',
arr[6]::int AS 'likesCount',
arr[7]::int AS 'repliesCount',
arr[8] AS 'replies'
FROM (
SELECT
ig_post_id,
json_extract(comments, ['id',
'text',
'ownerUsername',
'ownerProfilePicUrl',
'timestamp',
'likesCount',
'repliesCount',
'replies']) AS arr
FROM
(SELECT
ig_post_id,
unnest(json_extract(latestComments, '[*]')) AS comments
FROM raw_instagram_post
WHERE latestComments IS NOT NULL)
un) t;Done in 1 sec
+--------+
| status |
+--------+
| CREATE |
+--------+Проверим получившуюся таблицу:
SELECT * FROM silver_instagram_comments
LIMIT 5;Done in 1 sec
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| ig_post_id | comment_id | text | ownerusername | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| 3351813129396705531 | 18025641284105656 | "Your work apron is cool..\nDo Fjalraven sell them to the public?" | "dai_stick" | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| 3367108632665594085 | 18010752380180096 | "Well done 👏" | "alpencore" | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| 3362086677098626407 | 18041534590828292 | "Still made in cheap labour countries" | "leineleineleineleineleineleine" | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| 3362086677098626407 | 18028710974031364 | "🔥🔥🙌" | "arifwidie26" | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+
| 3361389062866375005 | 18012200105461376 | "Classic description of “type 2 fun”" | "itskate_g" | ... |
+---------------------+-------------------+--------------------------------------------------------------------+----------------------------------+-----+Результат 1: Популярность исполнителей
Теперь используем собранные выше данные, чтобы построить таблицу, в которой каждая строка соответствует одному исполнителю, а в столбцах представлена различная информация, так или иначе свидетельствующая о популярности этого исполнителя:
-
songs— количество композиций данного исполнителя -
ig_posts— количество постов с композициями данного исполнителя -
comments— количество комментариев в постах с композициями данного исполнителя -
tagged_users— количество затэганных пользователей в постах с композициями данного исполнителя -
likesCount— количество лайков в постах с композициями данного исполнителя -
repliesCount— количество реплаев в постах с композициями данного исполнителя
Для этого используем выражение LEFT JOIN.
Упорядочим финальную таблицу по третьему столбцу (ig_posts) по убыванию.
SELECT artist_name,
count(distinct song_name) AS songs,
count(distinct im.ig_post_id) AS ig_posts,
count(distinct comment_id) AS comments,
count(distinct user_id) AS tagged_users,
sum(likesCount) AS likesCount,
sum(repliesCount) AS repliesCount
FROM silver_instagram_musicinfo im
LEFT JOIN silver_instagram_taggeduser tu ON tu.ig_post_id=im.ig_post_id
LEFT JOIN silver_instagram_comments ic ON ic.ig_post_id =im.ig_post_id
GROUP BY 1 ORDER BY 3 DESC;Done in 1.6 sec
+-------------------+-------+----------+----------+--------------+------------+--------------+
| artist_name | songs | ig_posts | comments | tagged_users | likescount | repliescount |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| "telfarglobal" | 9 | 136 | 985 | 120 | 634 | 156 |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| "everlane" | 1 | 95 | 532 | 6 | 513 | 65 |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| "asos" | 3 | 93 | 503 | 60 | 583 | 85 |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| "victoriassecret" | 1 | 83 | 686 | 49 | 185 | 16 |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| "summerfridays" | 2 | 65 | 574 | 48 | 173 | 18 |
+-------------------+-------+----------+----------+--------------+------------+--------------+
| ... | ... | ... | ... | ... | ... | ... |
+-------------------+-------+----------+----------+--------------+------------+--------------+Эту таблицу можно сохранить в формат .xlsx, нажав на кнопку Download output as XLSX на данной ячейке. После этого в любом приложении для просмотра файлов .xlsx можно упорядочить собранные данные по любому столбцу, наложить дополнительные фильтры, скопировать данные или их часть для вставки в аналитические отчеты.
Сохраненный таким образом файл можно скачать здесь.
Результат 2: Распределение комментариев и событий в них во времени
Проанализируем распределение комментариев и событий в них (лайков и реплаев) в зависимости от времени, прошедшего от публикации поста до публикации данного комментария к нему — "свежести" комментария относительно поста, к которому он относится.
Для этого построим таблицу, в которой каждая строка будет соответствовать всем таким парам "пост — комментарий к нему", что между ними прошло 0 дней, 1 день и так далее до 9. И для всех таких пар выведем в столбцы:
-
comments— количество таких комментариев -
likescount— количество лайков у таких комментариев -
repliescount— количество реплаев у таких комментариев
SELECT
(comment_ts::DATE - post_ts::DATE)::INT AS days_till_comment,
count(DISTINCT comment_id) AS comments,
sum(c.likesCount)::int AS likesCount,
sum(c.repliesCount)::int AS repliesCount
FROM raw_instagram_post p
LEFT JOIN silver_instagram_comments c ON p.ig_post_id=c.ig_post_id
GROUP BY 1
ORDER BY 1
LIMIT 10;Done in 1.7 sec
+-------------------+----------+------------+--------------+
| days_till_comment | comments | likescount | repliescount |
+-------------------+----------+------------+--------------+
| 0 | 2876 | 1926 | 614 |
+-------------------+----------+------------+--------------+
| 1 | 3288 | 1847 | 460 |
+-------------------+----------+------------+--------------+
| 2 | 1980 | 830 | 189 |
+-------------------+----------+------------+--------------+
| 3 | 1352 | 635 | 102 |
+-------------------+----------+------------+--------------+
| 4 | 841 | 288 | 46 |
+-------------------+----------+------------+--------------+
| 5 | 610 | 230 | 26 |
+-------------------+----------+------------+--------------+
| 6 | 516 | 103 | 37 |
+-------------------+----------+------------+--------------+
| 7 | 411 | 88 | 26 |
+-------------------+----------+------------+--------------+
| 8 | 299 | 75 | 17 |
+-------------------+----------+------------+--------------+
| 9 | 249 | 96 | 17 |
+-------------------+----------+------------+--------------+Теперь в ячейке типа Python построим график по данным из этой таблицы. Для этого воспользуемся модулем Python matplotlib. Чтобы взять данные из предыдущей ячейки, используем переменную cell_output.
import matplotlib
plt = cell_output.plot(
title='Распределение комментариев и событий в них',
y=[
'comments',
'likescount',
'repliescount',
],
label = ['Комментариев', 'Лайков к комментарию', 'Реплаев к комментарию'],
ylabel='Количество',
x='days_till_comment',
xlabel = 'Дней между постом и комментарием',
figsize=(10,5),
)
plt.set_xticks(cell_output['days_till_comment'])
plt.get_figure()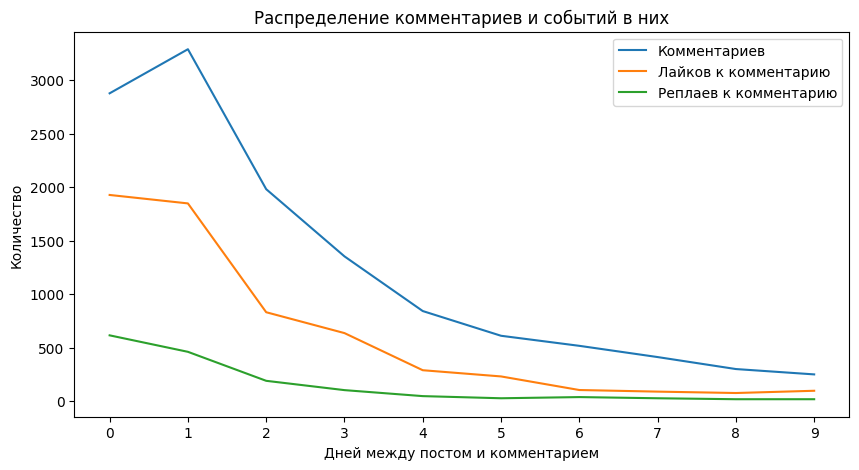
На графике хорошо видно, что количество комментариев к посту в первый день возрастает, а потом плавно снижается. Также видно, каким образом снижается активность внутри самих комментариев (лайки и реплаи к комментариям) в зависимости от устаревания комментария относительно даты поста.